 Octo: An Open-Source Generalist Robot Policy
Octo: An Open-Source Generalist Robot Policy
 Report
Report Code
Code Colab
Colab Weights
Weights








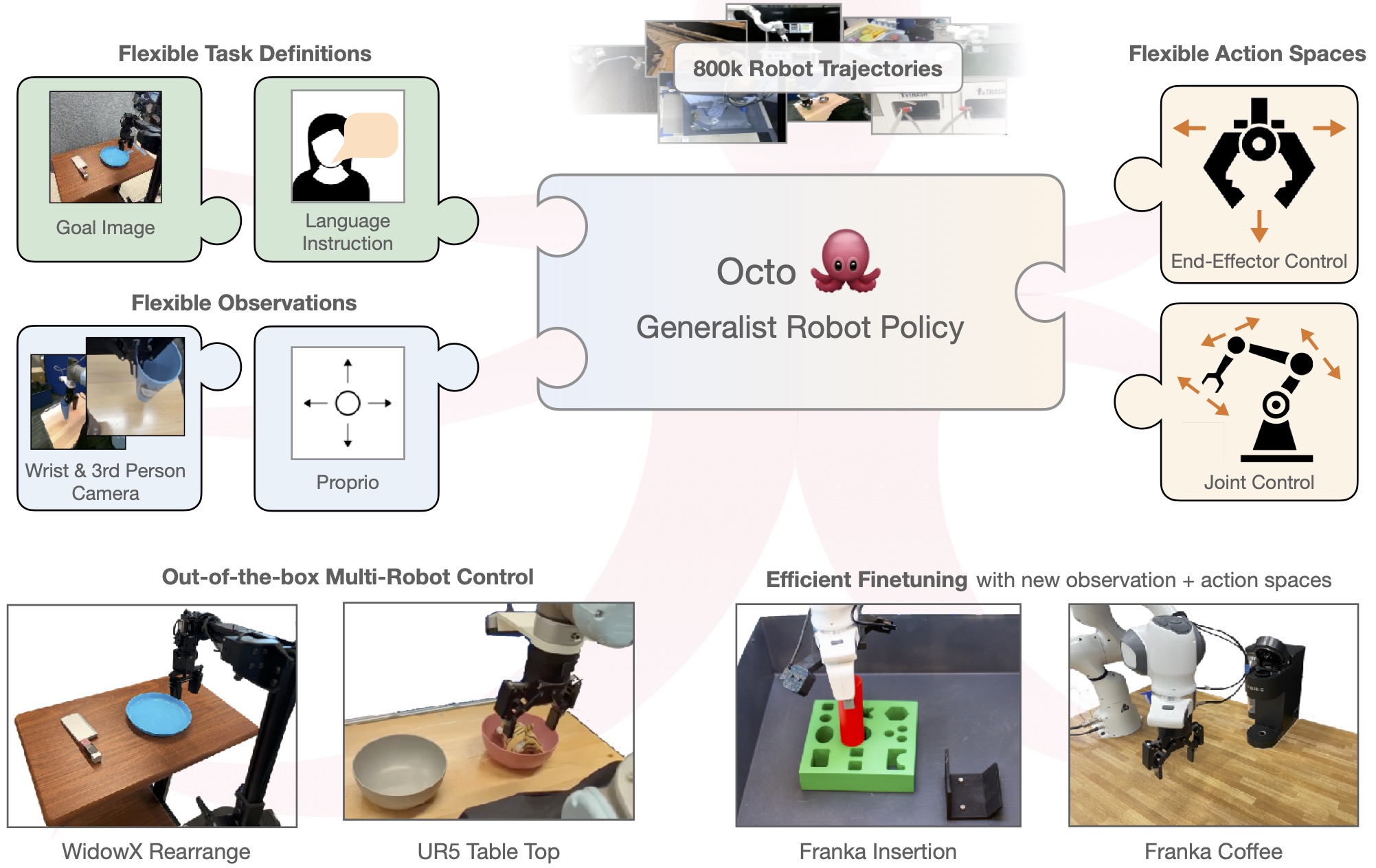
We introduce Octo , our ongoing effort for building open-source, widely applicable generalist
policies for robotic manipulation. The Octo model is a transformer-based diffusion policy,
pretrained on 800k robot episodes from the
Open X-Embodiment dataset. It supports
flexible task and observation definitions and can be quickly finetuned to new observation and
action spaces. We are introducing two initial versions of Octo, Octo-Small (27M parameters) and
Octo-Base (93M parameters).
The Model
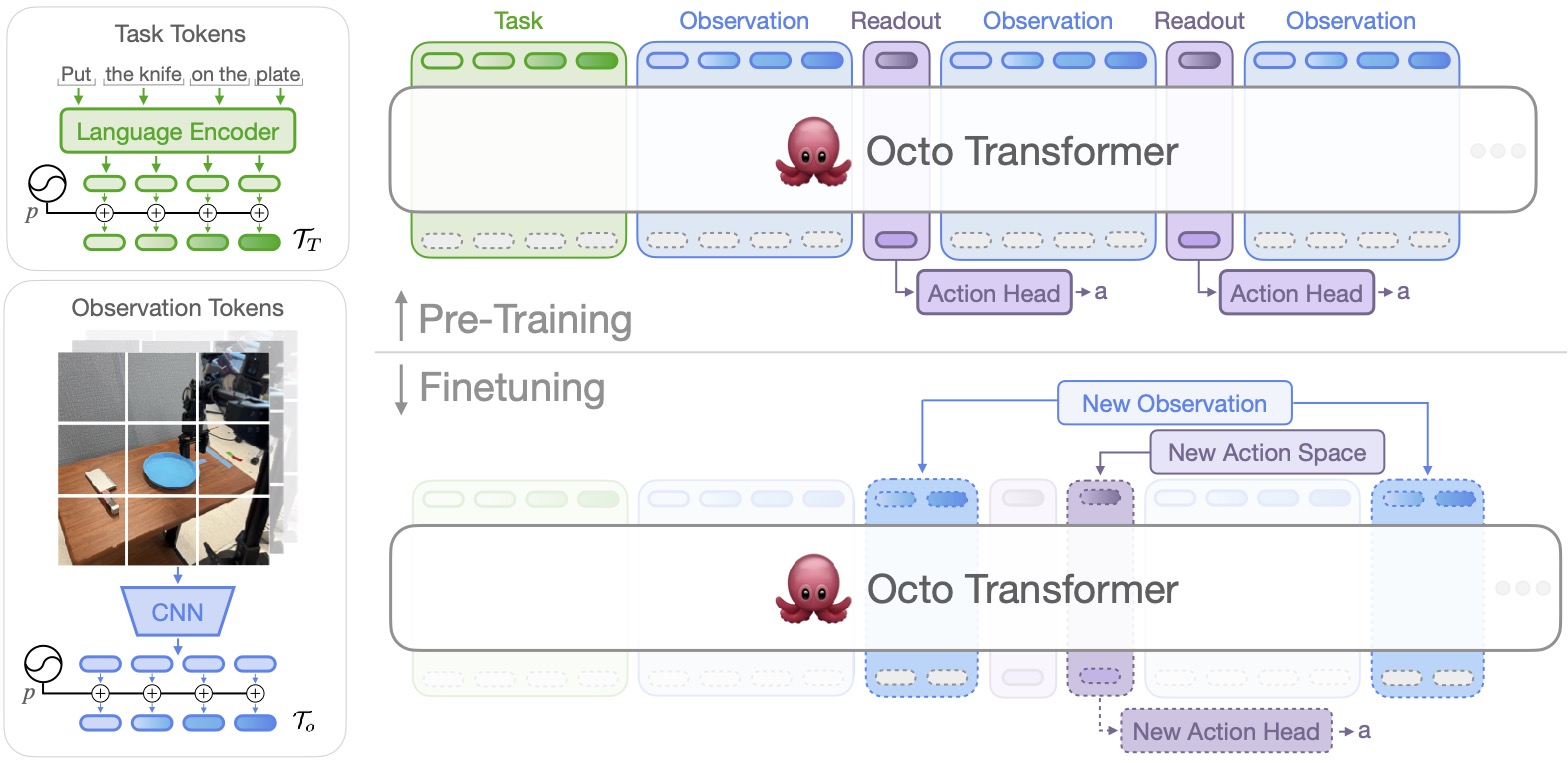
The design of the Octo model emphasizes flexibility and scale: the model is designed to support
a variety of commonly used robots, sensor configurations, and actions, while providing a generic
and scalable recipe that can be trained on large amounts of data. Octo supports both natural
language instructions and goal images, observation histories, and multi-modal action
distributions via diffusion decoding. Furthermore, we designed Octo specifically to support
efficient finetuning to new robot setups, including robots with different actions and different
combinations of cameras and proprioceptive information. This design was selected specifically to
make Octo a flexible and broadly applicable generalist robotic policy that can be utilized for a
variety of downstream robotics applications and research projects.
The Data
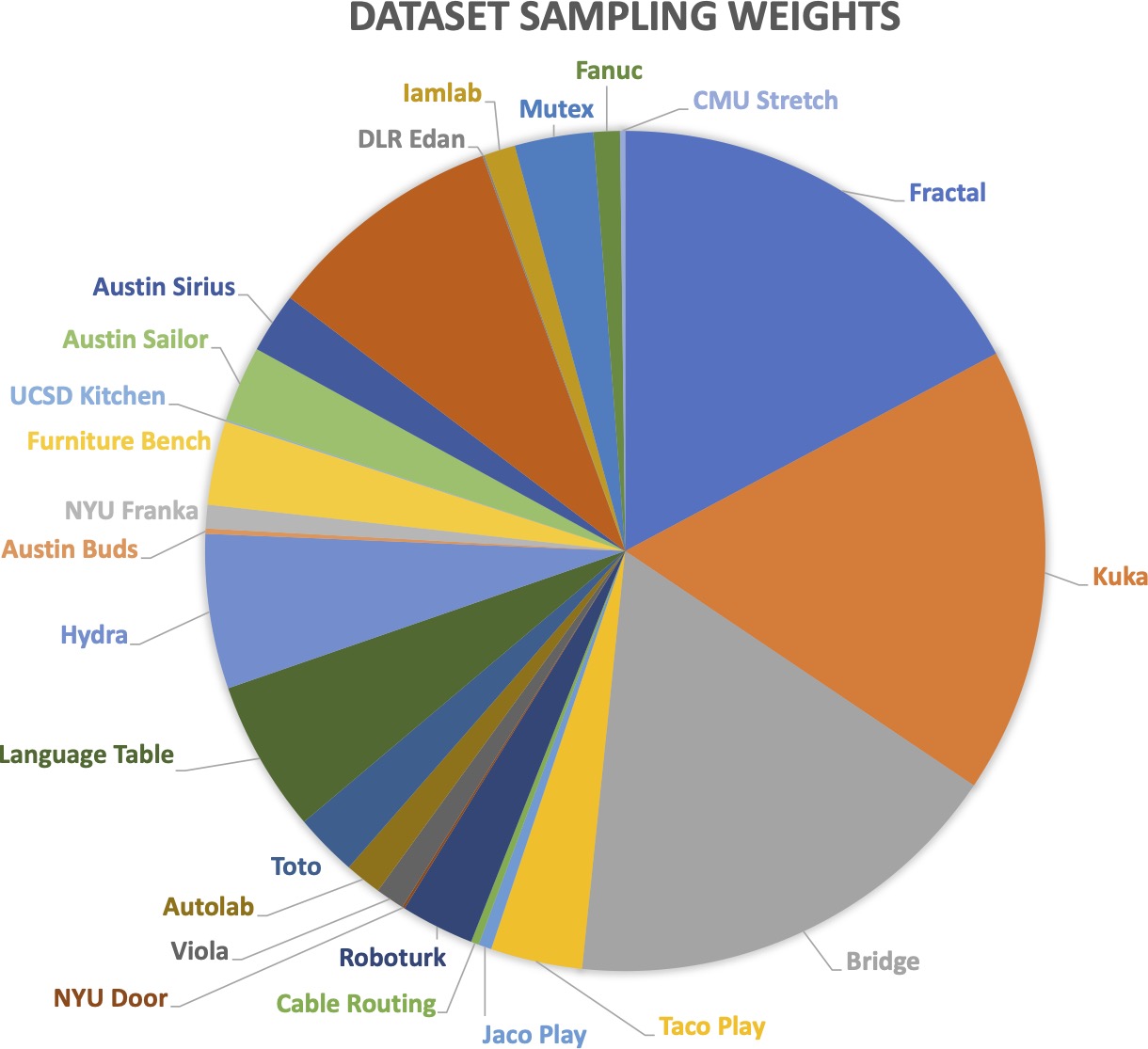
We train Octo on a mixture of 25 datasets from the Open X-Embodiment Dataset, a diverse
collection of robot learning datasets. Our training mixture includes data from a variety of
robot embodiments, scenes, and tasks. These datasets are heterogeneous not just in terms of the
robot type, but also in the sensors (e.g., including or not including wrist cameras) and labels
(e.g., including or not including language instructions).
The Results
We evaluate Octo on 9 real robot setups across 4 institutions. Our evaluations capture diverse
object interactions (e.g., "WidowX BridgeV2"), long task horizons (e.g., "Stanford Coffee") and
precise manipulation (e.g., "Berkeley Peg Insert"). We evaluate Octo's capabilities to control
robots in environments from the pretraining data out-of-the-box and to efficiently finetune to
new tasks and environments with small target domain datasets. We also test finetuning with new
observations (force-torque inputs for "Berkeley Peg Insert") and action spaces (joint position
control in "Berkeley Pick-Up").

| Zero-shot | |||
|---|---|---|---|
| WidowX | UR5 | RT-1 Robot | |
| RT-1-X | 0.20 | 0.35 | 0.60 |
| RT-2-X | 0.50 | — | 0.85 |
| Octo | 0.50 | 0.70 | 0.80 |
| Finetuning | |||||||
|---|---|---|---|---|---|---|---|
| CMU Baking | Stanford Coffee | Berkeley Peg Insert* | Berkeley Pick-Up† | Berkeley Bimanual† | Berkeley Coke | Average | |
| From Scratch | 0.25 | 0.45 | 0.10 | 0.00 | 0.20 | 0.20 | 0.20 |
| VC-1 | 0.30 | 0.00 | 0.05 | 0.00 | 0.50 | 0.10 | 0.15 |
| Octo | 0.50 | 0.75 | 0.70 | 0.60 | 0.80 | 1.00 | 0.72 |
Out-of-the-box, Octo can control multiple robots in environments from the pretraining data. When using natural language to specify tasks, it outperforms RT-1-X: the current best, openly available generalist robotic policy. It performs similarly to RT-2-X, a 55-billion parameter model. Additionally, while RT-1-X and RT-2-X only support language conditioning, Octo also supports goal image conditioning. On the WidowX tasks, we found that Octo achieved even better performance with goal image conditioning — 25% higher on average — likely because goal images provide more information about how to achieve the task.
We also find that finetuning Octo leads to better policies than starting from scratch or with the pretrained VC-1 weights. On average across the six evaluation setups, Octo outperforms the next best baseline by 52%. Each task uses ~100 target demonstrations. Importantly, we use the same finetuning recipe for all evaluation tasks, making this a good default configuration for Octo finetuning. The results also underline Octo’s ability to accommodate new observations (force-torque inputs for “Berkeley Insertion”), action spaces (joint position control for “Berkeley Pick-Up”) and new robot embodiments (“Berkeley Bi-Manual” and “Berkeley Coke”). This makes Octo applicable to a wide range of single and dual arm robotic manipulation problems that go beyond a single camera input and end-effector position control.
Citation
Please use the following BibTeX entry to cite this work:
@inproceedings{octo_2023,
title={Octo: An Open-Source Generalist Robot Policy},
author = {{Octo Model Team} and Dibya Ghosh and Homer Walke and Karl Pertsch and Kevin Black and Oier Mees and Sudeep Dasari and Joey Hejna and Charles Xu and Jianlan Luo and Tobias Kreiman and {You Liang} Tan and Lawrence Yunliang Chen and Pannag Sanketi and Quan Vuong and Ted Xiao and Dorsa Sadigh and Chelsea Finn and Sergey Levine},
booktitle = {Proceedings of Robotics: Science and Systems},
address = {Delft, Netherlands},
year = {2024},
}